Spark 시작하기 - 설치 및 Standalone
[환경]
Ubuntu 16.04.3 LTS
최근 Spark 공부를 하게 되면서 알게 된 내용들을 적어보려고 합니다.
이번 글에서는 Spark를 시작하기 위한 설치 부분과 단일 노드를 사용하는 Standalone 모드에 대해 다뤄보도록 하겠습니다.
Standalone 모드는 다른 클러스터 매니저를 사용하지 않고 Spark 만으로 클러스터를 구성하는 모드를 말한다. 단일 노드로도 구성할 수 있고, 복수의 노드로도 구성할 수 있다.
1. Apache Spark란?
Apache Spark는 오픈 소스 클러스터 컴퓨팅 프레임워크이다.
Scala, Java, Python 및 R의 고급 API를 지원하는 최적화 엔진을 제공한다.
Spark는 In-Memory 방식으로 Hadoop보다 빠른 속도를 보인다.
2. Apache Spark 설치
http://spark.apache.org/downloads.html 로 들어가서 3. Download Spark 부분을 눌러주면, 다운로드 링크들이 나온다. HTTP아래의 링크를 하나 복사하여 wget을 통해 다운받아준다.
# cd ~
# wget http://apache.mirror.cdnetworks.com/spark/spark-2.3.1/spark-2.3.1-bin-hadoop2.7.tgz다운이 완료되면 tar을 통해 압축을 풀어준다.
# tar -xf spark-2.3.1-bin-hadoop2.7.tgz설치가 완료되면 이제 Spark 사용을 위한 환경설정을 해준다.
3. Standalone을 위한 환경설정
우선 .bashrc 파일에 환경변수를 추가해준다.
SPARK_HOME 환경변수와 Spark의 bin 디렉토리의 경로를 PATH에 추가해준다. MASTER 변수는 편의를 위해 추가해주었다.
.bashrc 파일
# vi .bashrc
export SPARK_HOME=/home/hoyy/spark-2.3.1-bin-hadoop2.7
export PATH=${SPARK_HOME}/bin:${PATH}
export MASTER=spark://spark-master:7077
다음으로 ${SPAKR_HOME}/conf/ 경로에 있는 spark-env.sh.temtlate과 spark-defaults.conf.template을 복사한 후 내용을 추가해준다.
# cd ${SPARK_HOME}/conf
# cp spark-env.sh.template spark-env.sh
# cp spark-defaults.conf.template spark-defaults.conf
먼저 spark-env.sh에 다음의 내용들을 추가해준다.
spark-env.sh파일
# vi spark-env.sh
export SPARK_MASTER_IP='192.168.80.128'
export SPARK_MASTER_HOST=spark-master
export SPARK_MASTER_WEBUI_PORT=7777
export SPARK_WORKER_INSTANCES=2
export SPARK_EXECUTOR_CORES=1
export SPARK_EXECUTOR_MEMORY=1g
SPARK_MASTER_IP는 말 그대로 MASTER 노드의 IP이다. 하나의 노드만 사용할 것이니 현재 노드의 IP를 넣어주자.
SPAKR_MASTER_HOST는 MASTER의 호스트이다. 아래에서도 언급하겠지만 spark-env.sh에 적어놓은 호스트를 /etc/hosts 파일에도 적어놓아야 한다.
WORKER_INSTANCES, EXECUTOR_CORES, EXECUTOR_MEMORY는 각각 worker의 수, executor 하나의 코어 수, executor 하나의 memory이다.
이제 spark-defaults.conf의 가장 아래에 있는 spark.master 항목과 spark.serializer 항목의 ‘#’을 지우고 내용을 수정해준다.
spark-defaults.conf파일
# vi spark-defaults.conf
spark.master spark://spark-master:7077
spark.serializer org.apache.spark.serializer.KryoSerializer
Apache Spark에서는 빅데이터 애플리케이션을 위해 KryoSerializer을 사용하는 것이 좋다고 한다.
마지막으로 /etc/hosts 파일에 호스트를 추가해준다.
/etc/hosts파일
# sudo vi /etc/hosts
192.168.80.128 spark-master
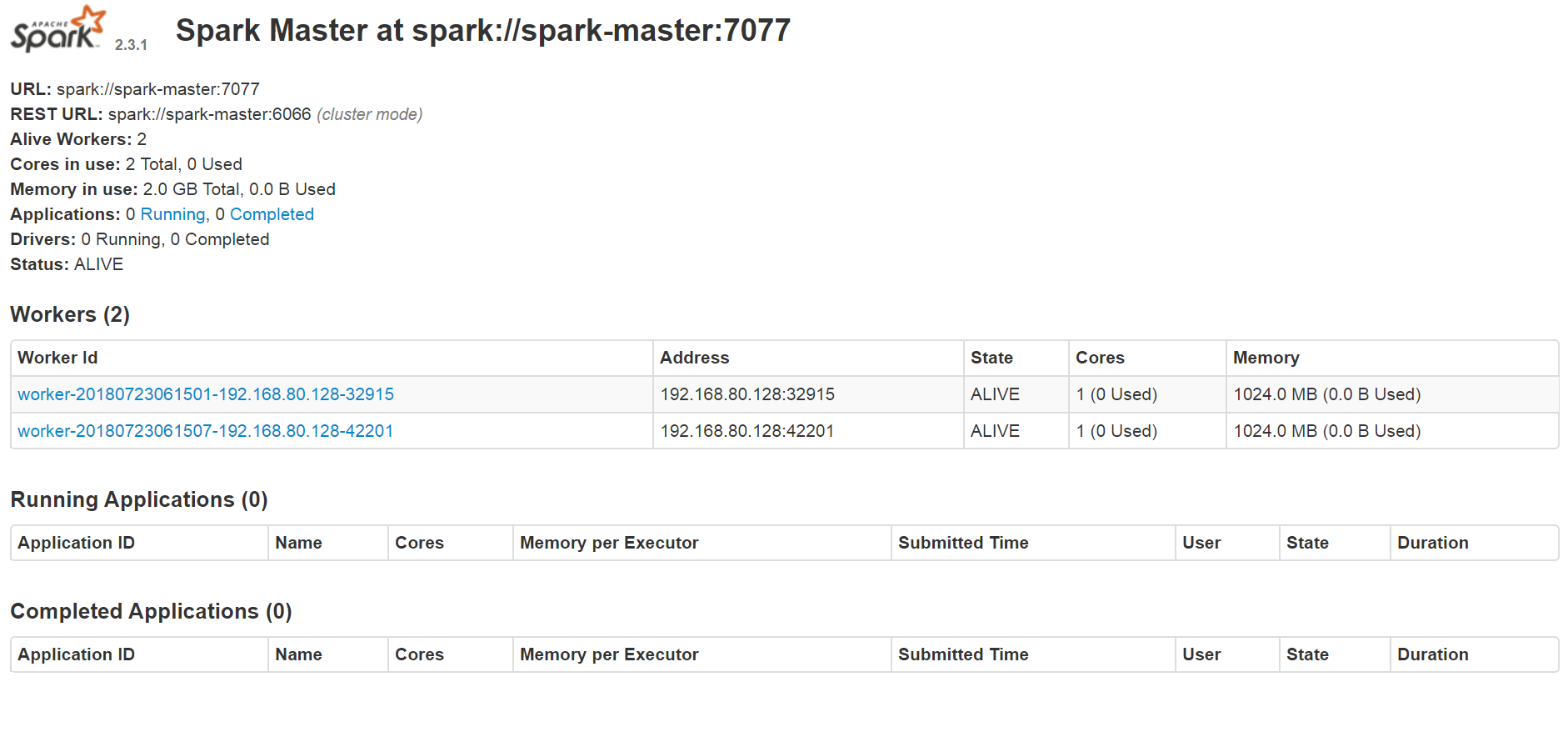
4. Spark 실행
# cd ${SPARK_HOME}/sbin
# ./start-master.sh (마스터노드 실행)
# ./start-slave.sh ${MASTER} (워커노드 실행)
[참고 사이트]
https://spark.apache.org/docs/latest/spark-standalone.html
http://spark.apache.org/docs/latest/tuning.html#data-serialization